Re-DreamerV3 🤖
Abstract
We enhance DreamerV3 by integrating Transformer-based SSMs and a novel stochastic replay prioritization, combining TD-error based PER with novelty-driven CR. The modifications improved sample efficiency in a sparse-reward ‘Private Eye’ Atari task. However, generalization was limited, with performance hindered in the dense-reward continuous control tasks of ‘Walker Run’ and visual ‘Cheetah Run’. We have open-sourced our implementation.1
Introduction
DreamerV3 [1], a prominent model-based reinforcement learning agent, achieves strong sample efficiency by learning a world model with a Recurrent State Space Model (RSSM) [2] and training a policy on imagined trajectories. However, opportunities exist to further enhance its capabilities. For instance, its uniform replay sampling overlooks advances like Prioritized Experience Replay (PER) [3], [4], [5] and Curious Replay (CR) [6] that improve data reuse. Moreover, while its RSSM effectively captures short-term dynamics, Transformer-based world models offer potential for superior long-term credit assignment and sample efficiency [7], [8], [9], [10], an area underexplored in DreamerV3.
This work explores several key modifications to the DreamerV3 framework. We introduce a unified replay prioritization strategy that stochastically combines PER and CR, and adopt a Transformer-based State Space Model (SSM) as the world model’s backbone. To further stabilize learning and improve architectural robustness, we also explore replacing traditional CNNs with ConvNeXt [11] blocks, employing an Entropy-Guided Unimix for categorical distributions, and utilizing a Symmetric Log-Cosh Loss for the decoder. These collective modifications are designed to improve data efficiency and the modeling of complex temporal dynamics.
Methodology
Transformer-based World Models
To improve sequence modeling in complex environments, we propose several architectural enhancements over traditional RSSMs.
Transformer-Based Dynamics Core: Inspired by TransDreamer [7], we replace the conventional GRU-based recurrent core with a transformer-based state-space model. This allows the model to leverage self-attention mechanisms to capture long-range temporal dependencies more effectively. To retain positional information crucial for sequential modeling, we integrate rotary position embeddings (RoPE) [12] into the attention mechanism. We incorporate Gated Linear Units (GLUs) [13] within the transformer’s feedforward layers to enhance non-linear capacity and improve gradient flow.
The input sequence to the Transformer was created by stacking the deterministic state, stochastic state, and action representations. We experimented with multiple approaches to obtain the update of the deterministic state from the Transformer output, discussed in the results section.
Entropy-Guided Unimix: To stabilize training and avoid overly confident predictions that cause KL loss spikes, we use an adaptive uniform mix strategy for categorical distributions. Instead of applying a fixed mixture of the model’s predicted distribution (99%) and a uniform distribution (1%) [1], we adapt the mixture ratio based on the entropy of the prediction—applying more smoothing when entropy is low (i.e., the model is overconfident) and less when uncertainty is already high. This dynamic adjustment encourages balanced exploration while still allowing sharp predictions when justified.
ConvNeXt Encoders/Decoders: We explore replacing standard convolutional architectures in the encoder and decoder modules with ConvNeXt blocks [11]. This aims to enhance the model’s ability to extract and reconstruct visual features through deeper and more expressive convolutional layers, without sacrificing inductive biases favorable to image-based tasks.
Symmetric Log-Cosh Loss: We incorporate the SymLog-Cosh loss as a robust alternative to standard loss functions for regression tasks involving wide dynamic ranges. This loss combines the benefits of symmetric logarithmic transformation with the smooth, outlier-resistant properties of the log-cosh function. It behaves similarly to Mean Squared Error (MSE) for small deviations while transitioning to a linear growth regime for large errors, akin to Mean Absolute Error (MAE). This makes it especially suitable for handling targets with large magnitudes, ensuring stable and effective learning across varied scales.
Stochastic Combination of PER and CR
To enhance DreamerV3’s [1] sample efficiency, we introduce PER+CR, a replay strategy stochastically combining Prioritized Experience Replay (PER) [3] and Curious Replay (CR) [6].
For the PER component, we use DreamerV3’s value estimates $V(x)$ calculated by its critic component to calculate TD errors ($\delta_t = r_t + \gamma V(x_{t+1}) - V(x_t)$), assigning priority $p_i = (|\delta_t| + \epsilon)^\alpha$ to guide world model learning from surprising dynamics. For the CR component, we use its standard curiosity signal combining count-based novelty ($c\beta^{v_i}$) and model prediction error ($(L_i| + \epsilon)^\alpha$), yielding priority $p_i = c\beta^{v_i} + (|L_i| + \epsilon)^\alpha$ to target novel/challenging experiences ($v_i$: sample count, $c, \beta$: novelty params, $L_i$: world model loss).
In our PER+CR approach, at each sampling step, either the PER-based prioritization (with probability $f$) or CR-based prioritization (with probability $1-f$) is selected. Experiences are then sampled according to the chosen strategy’s priorities. This stochastic selection, as opposed to a weighted sum, is chosen to leverage the complementary strengths of PER and CR by maintaining their distinct learning signals and avoiding the complex hyperparameter tuning required to balance their potentially disparate priority ranges, ultimately aiming for more robust and efficient learning.
Environments
For rapid yet insightful experimentation, we selected a subset of less computationally intensive tasks from the original DreamerV3 paper, chosen to highlight sample efficiency and robust learning. These include Private Eye (Atari100k [14]), a visual task with sparse rewards and a 100k step limit demanding sample efficiency; Cheetah Run (DeepMind Control [15]), a visual continuous control task testing complex dynamics learning from pixels with dense rewards for forward velocity; and Walker Run (DeepMind Control [15]), a continuous control task challenging learning from lower-dimensional proprioceptive inputs with dense rewards for forward movement.
Results
This section presents results from our reproducibility study, prioritized replay, and transformer-based world model experiments. All runs used a single NVIDIA A100 (40 GB). Learning curves show mean performance with shaded regions showing standard deviation across seeds.
Reproducibility Study
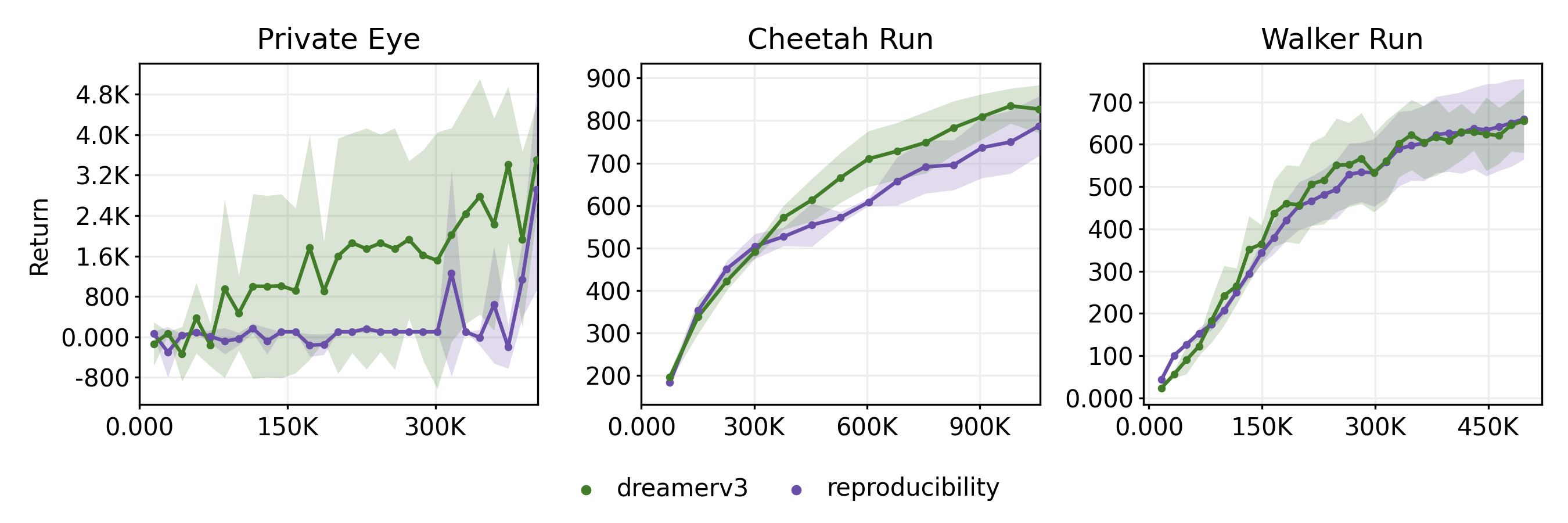
To establish a performance baseline, we ran DreamerV3’s [1] publicly available codebase2 on the selected tasks using 3 random seeds each. Figure [1] compares our learning curves against DreamerV3’s officially reported performance (originally 5 seeds for ‘Private Eye’/’Walker Run’, 9 for ‘Cheetah Run’). Our reproduction results are broadly consistent and generally fall within the standard deviation of the original DreamerV3 reports. Minor variations, particularly the high episode score discrepancy observed in the sparse-reward task ‘Private Eye’, are likely attributable to run-to-run variance given our limited number of seeds. Overall, these reproductions confirm the robustness of the experimental setup, providing a reliable baseline for evaluating our proposed modifications.
ConvNeXt Blocks
We explored replacing the standard CNN-based encoder and decoder modules with ConvNeXt blocks, while retaining the original RSSM dynamics. The hypothesis was that a modern convolutional architecture might yield better visual features. However, this change led to no measurable gains in performance and significantly increased training time. These results suggest that ConvNeXt may be overly complex for the image-based environments as the current simple enough CNN-based variational auto encoders seem to do their job well enough. For all further experiments, we used the original CNN implementation for the Encoder and Decoder components.
Transformer-based world models
To better capture long-range temporal dependencies, we replaced the GRU-based core of the Recurrent State Space Model (RSSM) with a Transformer. We evaluated three different approaches for updating the deterministic state from the Transformer output:
Last Token: The final hidden state from the Transformer was projected to the deterministic state dimension. While a few episode returns spiked early, most runs showed no improvement over time, underperforming compared to the baseline. This suggests the last token cannot capture enough relevant information about the dynamics of the environment.
Gated Output: The full Transformer output was processed using GRU-style gating to control the update. This method underperformed in the ‘Private Eye’ task, but showed promise in dense-reward environments.
Mean Pooling: All token outputs were averaged and projected, followed by a residual connection with the previous deterministic state. This approach showed the most promise for Private Eye and performed on par or better than the baseline, but struggled in ‘Walker run’ and ‘Cheetah run’.
We decided to perform all subsequent experimentation using Mean Pooling for the ‘Private Eye’ task and Gated Output for the other two tasks (Figure [2]).
The use of the Entropy-Guided Unimix saw an improvement in the learning dynamics, showing fewer loss spikes and more stable learning of the environment dynamics overall.
The Symmetric Log Cosh loss was only applicable to proprioceptive control tasks with vector environment representation - in our case only ‘Walker Run’. We see an improvement in the prediction loss in the early stages of training compared to the reproduction runs, but the losses become identical at later stages. Testing on environments with different reward scales is needed to determine the effectiveness of this loss.
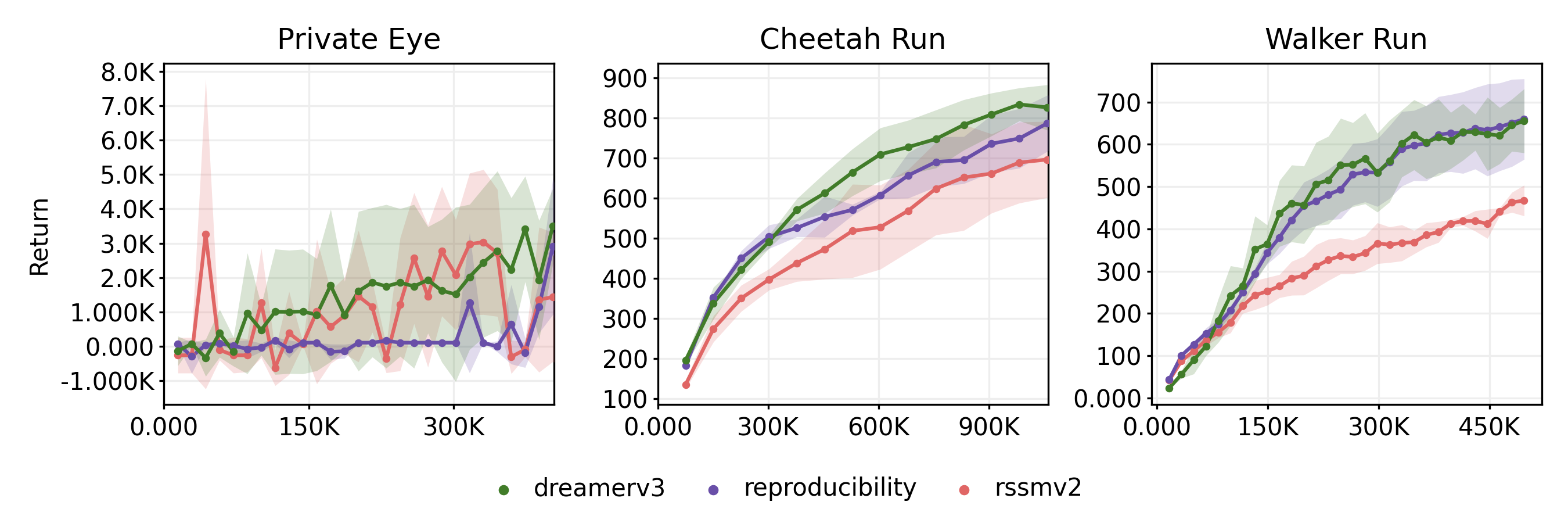
We ran the experiments for 3 seeds on all environments using the Transformer-based SSM, Entropy-Guided Unimix and Symmetric Log Cosh loss with the results shown in Figure [2]. Overall, we manage to match the performance of DreamerV3 on ‘Private Eye’ and are within a reasonable range of the episode scores in ‘Cheetah Run’, but the Transformer struggles in the proprioceptive control task.
Replay Prioritization
We investigated the impact of different replay prioritization strategies, selecting ‘Private Eye’ and ‘Walker Run’ as primary testbeds due to computational constraints. We applied PER ($\alpha = 0.6, \epsilon = 1e-6$ [3]), Curious Replay (CR; $\beta = 0.7, \alpha = 0.7, c = 1e4, \epsilon = 0.1$ [6]), and their stochastic combination (PER+CR). As shown in Figure [3], these strategies showed domain-dependent efficacy.
On ‘Private Eye’, a sparse-reward task requiring hard exploration, all prioritization methods, including PER+CR, outperformed uniform replay in terms of sample efficiency. The PER+CR combination (50/50 mix) demonstrated results comparable or slightly superior to PER or CR alone, suggesting a synergy between these two complementary methods. Conversely, on ‘Walker Run’, a dense-reward continuous control task, all prioritization approaches, including PER+CR, reduced overall rewards. This likely stems from oversampling "surprising" failure events (e.g., the walker falls with high TD/model errors), diverting learning from stable locomotion dynamics where uniform sampling excelled. These findings highlight that prioritization benefits are highly sensitive to an environment’s reward structure and learning challenges.
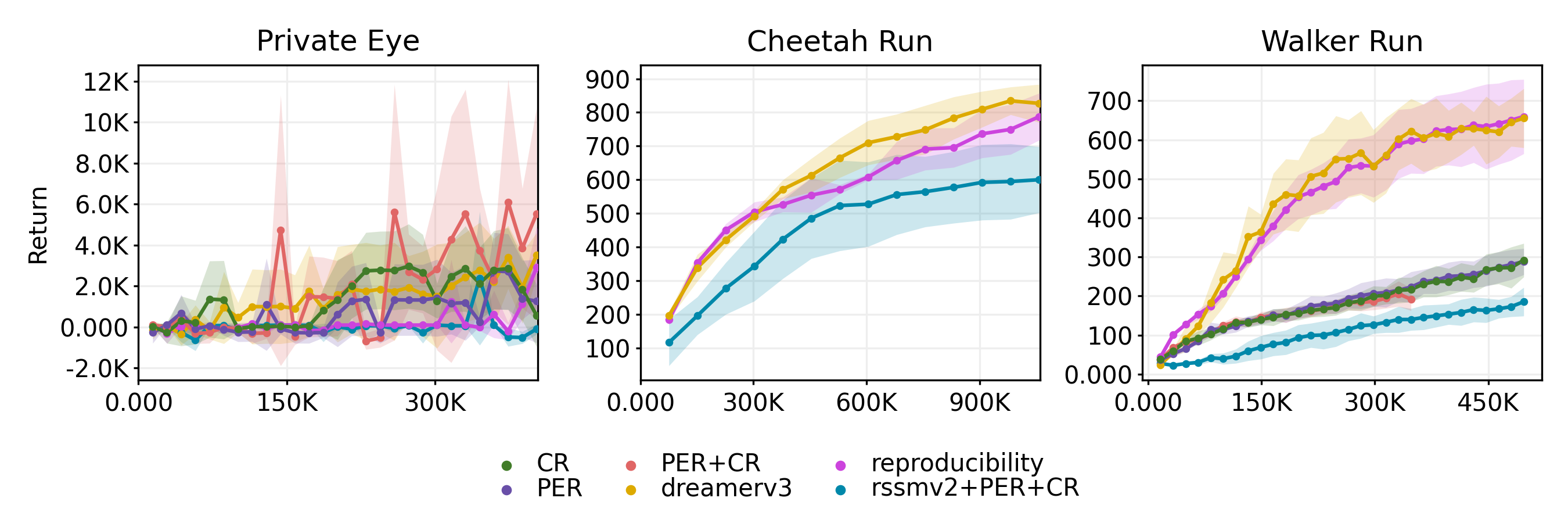
Combining the Transformer-based SSM with 50% PER + 50% CR stochastic replay (Figure [3]) surprisingly resulted in poor performance across all environments. This contrasts with the individual successes of the Transformer SSM and PER+CR on ‘Private Eye’. We hypothesize the Transformer’s higher capacity caused it to overfit to the ‘surprising’ experiences prioritized by PER+CR, thereby neglecting essential general dynamics - a vulnerability less apparent with the GRU-based model.
Conclusion
Our proposed enhancements to DreamerV3—integrating Transformer-based state-space models and a stochastic replay prioritization strategy (PER+CR)—demonstrated improved sample efficiency in sparse-reward environments like Private Eye. The Transformer core and novel replay strategy effectively supported exploration and long-term credit assignment. However, generalization suffered in dense-reward environments due to Transformers overfitting biased replay data—an issue not observed with the original GRU-based model. Due to computational budget and time constraints, evaluations were limited in scale and diversity. Future work should scale evaluations, refine Transformer integration, and develop environment-adaptive prioritization to ensure robustness across diverse tasks, including open-ended domains like Minecraft.
References
- [1] D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,” Nature, pp. 1–7, 2025.
- [2] D. Hafner et al., “Learning latent dynamics for planning from pixels,” in International conference on machine learning, 2019, pp. 2555–2565.
- [3] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv:1511.05952, 2015.
- [4] V. Mnih et al., “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
- [5] M. Hessel et al., “Rainbow: Combining improvements in deep reinforcement learning,” in Proceedings of the AAAI conference on artificial intelligence, 2018, vol. 32.
- [6] I. Kauvar, C. Doyle, L. Zhou, and N. Haber, “Curious replay for model-based adaptation,” arXiv preprint arXiv:2306.15934, 2023.
- [7] C. Chen, Y.-F. Wu, J. Yoon, and S. Ahn, “TransDreamer: Reinforcement Learning with Transformer World Models.” 2024, [Online]. Available at: https://arxiv.org/abs/2202.09481.
- [8] V. Micheli, E. Alonso, and F. Fleuret, “Transformers are Sample-Efficient World Models.” 2023, [Online]. Available at: https://arxiv.org/abs/2209.00588.
- [9] W. Zhang, G. Wang, J. Sun, Y. Yuan, and G. Huang, “STORM: Efficient Stochastic Transformer based World Models for Reinforcement Learning.” 2023, [Online]. Available at: https://arxiv.org/abs/2310.09615.
- [10] M. Burchi and R. Timofte, “Learning Transformer-based World Models with Contrastive Predictive Coding.” 2025, [Online]. Available at: https://arxiv.org/abs/2503.04416.
- [11] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A ConvNet for the 2020s.” 2022, [Online]. Available at: https://arxiv.org/abs/2201.03545.
- [12] J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen, and Y. Liu, “RoFormer: Enhanced Transformer with Rotary Position Embedding.” 2023, [Online]. Available at: https://arxiv.org/abs/2104.09864.
- [13] N. Shazeer, “GLU Variants Improve Transformer.” 2020, [Online]. Available at: https://arxiv.org/abs/2002.05202.
- [14] L. Kaiser et al., “Model-based reinforcement learning for atari,” arXiv preprint arXiv:1903.00374, 2019.
- [15] Y. Tassa et al., “Deepmind control suite,” arXiv preprint arXiv:1801.00690, 2018.